

Adventures in AI: Addressing a Fundamental Challenge Facing Banks’ ISO 20022 Migrations

In this blog, Jamie Packham, shares his own experiences deploying generative artificial intelligence (AI) models and explores the potential for AI to help accelerate banks’ migration to the ISO 20022 messaging standard.
The emergence of ChatGPT in 2022 caused a global media storm and has since redefined the way we think about, and are now approaching, generative AI in banking. In fact, a recent independent survey conducted by Celent found that around 55% of banks are currently evaluating or testing generative AI in some capacity, while 36% think the tech will have the greatest impact on the market in five years.
Exploring the AI opportunity
At Icon, we have also been experimenting with AI capabilities and, back in November 2023, a new project landed on our desks. Could we use AI to revolutionise documentation for our clients? As a self-confessed sceptic that saw AI as a glorified search engine, I went in with little to no expectations.
After establishing certain criteria (the model had to be open-source and self-hosted as we would be feeding it data) and leaning on our in-house experts, we initially landed on using Llama 2 code instruct 30B for the project. Having studied the capabilities, we then had a moment of realisation: the possibilities for AI extended far beyond documentation and had the potential to transform not only client servicing, but also the software development process.
Emboldened, we deployed the model onto two g4dn GPUs on an ubuntu AWS instance. All well and good, until we fired a question through and the whole thing crashed. After an investigation, it transpired the minimum processing requirements for deploying this particular model was the hugely expensive and elusive Nvidia A100 GPU. This brought us to another realisation: AI was not a cost-efficient way to improve our documentation.
Our initial experimentation had inadvertently encapsulated the much larger challenge facing banks and their development teams, in that even relatively simple use-cases require massive computing power at significant cost. This means that banks must direct their resources towards the use-cases that can deliver meaningful returns.
Happily, one such use-case was brought to our attention: transforming unstructured name and address data into an ISO 20022-based structured format. Considering the discourse surrounding the world-altering implications and applications of AI, on the surface this may seem somewhat underwhelming. Yet it has the potential to be a game-changer.
Addressing a key challenge for ISO 20022
As part of the migration to ISO 20022 payment messages, organisations need to transform ‘unstructured’ name and address data into fully (or hybrid) structured names and addresses. While this can help to significantly reduce the friction associated with processing cross-border payments, it presents considerable challenges.
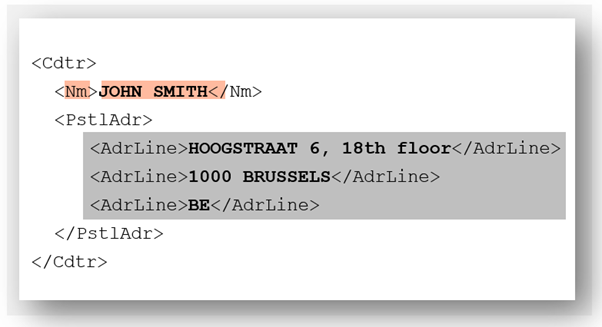
This is because to account for the huge variability in address formats across different countries (not to mention languages and scripts), a fully structured address in ISO 20022 contains myriad address fields including street name, building name, building number, floor number, postal code, town name, country subdivision and country code. Most data sources do not provide address data at such a granular level, which presents problems for involved parties to support fully structured addresses.
Traditional technology is often not fit for purpose to solve this issue, while manual intervention is very costly and not feasible when transactions need to be processed in real-time. This is where AI can bring a meaningful outcome. In particular, large language models (LLMs) – leveraging their contextual understanding of language – emerge as excellent candidates for address parsing. Their capacity to grasp context enables them to decipher intricate address variations, language-specific structures and nuanced expressions, making them highly proficient in navigating the inherent complexity of diverse address formats worldwide.
Converting unstructured address data with AI
With this revised focus, it was time to go back to the drawing board. As the model no longer needed to be aware of how to code, we downgraded to Llama 2 7b. But once again, the problems started to unfold as we started firing in questions. The answers needed to be in the same expected format so that they could be unmarshalled into an object and applied to the payment object. However, the information was buried within a paragraph text and the JSON itself was not enriching the data. To compound the issue, the information was mostly incorrect.
It was decision time. Continue using a high parameter trained llama 2 model? Or switch tactics and explore the feasibility and reliability of the ChatGPT API?
We decided to pivot to ChatGPT (naturally using the premium version to address data privacy and security considerations). While similar problems remained – in that questions were returned with text as well as the JSON object – the JSON object was being enriched and everything looked to be formatted correctly. It was now a case of refining the prompt of the API, as well as the question. Importantly, ChatGPT added a feature that forces the answer to be returned in a JSON format. After further iterations over three days, we achieved a level of consistency, and it was time to hook it up into the payment journey. This was relatively simple and resulted in the whole object being replaced with the new postal address.
Of course, if this was to go-live then further refinement would be required. For example, the model was mapping the unstructured addresses into the ‘adrLine’ field as well as the structured addresses. In addition, the query didn’t always generate a response – even when sending the exact same question with the same data reply. This caused the API call to fail at a rate of approximately 10%.
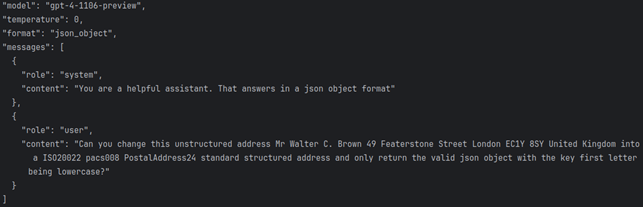
Request Prompt
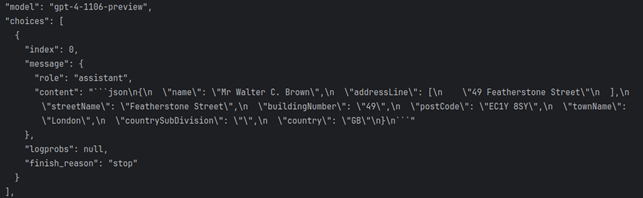
Response
So, what can we learn from this initial exploration?
Firstly, there is clear potential for AI to support the conversion of unstructured name and address data into structured data to support ISO 20022 migrations. Looking further ahead, there are likely other opportunities to leverage AI more widely to target specific use-cases and deliver incremental improvements.
Yet these improvements will likely take time and come at a cost. We therefore caution banks, as with any new and emerging technology, to not overestimate the potential when it comes to revenue and margin gains, ensuring that they carefully evaluate the areas where AI can deliver value and understand the associated cost factors.
Jamie Packham