

Detecting Fraud in An Imbalanced Payments World

There’s been a lot in the press recently about the benefits Machine Learning offers when it comes to fraud detection. However, there are limitations. In reality, most of the payments transactions made are legitimate – so with the lack of fraudulent ‘examples’, how can we train Machine learning models to differentiate between the genuine and the not?
The ratio of fraudulent to non-fraudulent transactions was much less of an issue with rule-based systems (a byproduct of a previous wave of Artificial Intelligence, the Expert System) as rules were manually created by people observing patterns that indicate a fraud. An example of a rule would be to flag a transaction if it is above a threshold and from a location that the customer hasn’t bought from previously.
Yet, these rule-based systems are now creaking at the seams as the number of payments transactions has grown dramatically, driven by:
- Increasing numbers of mobile customer payments
- Customers moving from cash-based payments to digital payments,
- Instant payments requiring payment transactions to be settled in a matter of seconds
This ‘tsunami of payments volumes’ means that there is an even greater opportunity for fraud to take place.
So, if rule-based systems are struggling to keep up in this open, digital world, there is a greater need for Machine Learning systems to learn from imbalanced transaction histories. But just how easy is this to do?
I recently had the opportunity to speak on this topic at the excellent Minds Mastering Machines conference in London and demonstrated the following techniques to deal with imbalanced transaction data.
A complex challenge to solve
The problem with imbalanced data is that you can easily obtain high accuracy, without generating any worthwhile insights. At the conference, I demonstrated this using a Kaggle dataset of anonymised fraud transactions. I was quickly able to obtain accuracy of 99.83% – which seemed impressive until my analysis showed that the model wasn’t detecting any frauds! The reason that this happened was that the model trained on the majority dataset, the non-fraudulent transactions – and ignored the 0.172% of the transactions over the two-day timespan that were fraudulent ones.
Addressing the problem of training a neural network with imbalanced data is not a simple one. When I extracted the first non-fraudulent transactions to ensure that there was an equal number of fraudulent and non-fraudulent transactions, the accuracy dropped to a paltry 49%. This is hardly surprising; to balance the data I had removed 283823 out of 284315 records and in the process, generated a large data loss. To solve the issue, I needed to improve the quality of the data and then address the imbalance by either undersampling or oversampling.
Improving data quality
In order to improve the quality of the data that is used to train the fraud-detection model, a number of analytical methods were applied. Having ensured that all the elements were scaled to fall within the same range, a correlation matrix was generated to highlight which features are most relevant in detecting fraudulent transactions.
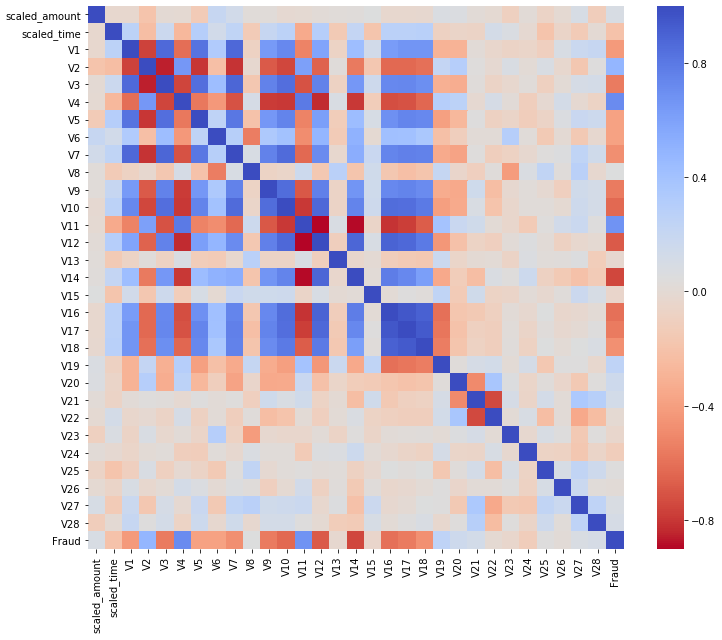
Looking at the bottom row (Fraud) of the Correlation Matrix shown above, it is possible to identify which features are most influential:
- the darker blue elements are positively correlated; if V2, V4 or V11 have a higher value it is more likely that the transaction is a fraudulent one.
- the darker red ones are negatively correlated, so lower the value of V3, V12 or V14 the more likely that the transaction is a fraudulent one.
Improving the accuracy
To improve the accuracy of the fraud detection method, outliers should be removed. Outliers are extreme values that are outside of the range of other observations. For example, a temperature of over 50 degrees Celsius is likely to be an outlier in a table of UK weather forecasts.
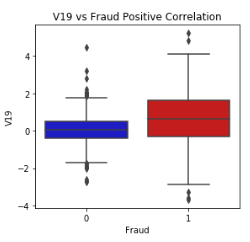
The boxplot shows the median and extremes, with outliers beyond the extremes. In this example, the non-fraudulent transactions are on the left, and the fraudulent transactions are on the right. The threshold for removing outliers requires tuning; if the threshold is too low, useful data could be lost and if it is too high, outliers could remain and reduce the accuracy of the model. By removing extreme outliers on the critical fields identified in the Correlation Matrix the accuracy was improved.
Could we predict fraud from the dataset?
Once the extreme outliers were removed for the features identified in the correlation matrix, the next question is: does the dataset have the potential to indicate whether a transaction is fraudulent or not? To do this the t-SNE algorithm, which takes a multi-dimensional dataset and reduces it a lower-dimensional graph, was applied.
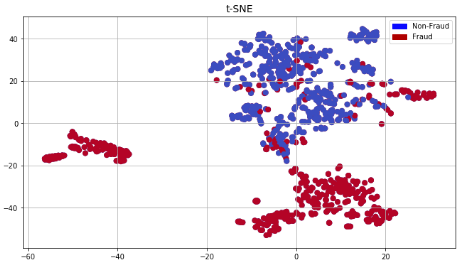
As shown above, the algorithm was able to detect fraudulent and non-fraudulent clusters, indicating that machine learning models have the potential to separate fraudulent transactions from non-fraudulent transactions.
To address the imbalance in the data between the large number of non-fraudulent transactions and fraudulent transactions, there are two options:
- Reduce the number of non-fraudulent transactions to balance with the number of fraudulent transactions while minimising data loss, using random under-sampling.
- Create synthetic points from the fraudulent class using a technique such as SMOTE.
After applying random undersampling to reduce the number of non-fraudulent transactions and SMOTE to generate new synthetic points to the fraudulent class, both datasets were fed into the following model, which consisted of one input layer with a node for each feature, a hidden layer and an output layer with two nodes (one for fraud and one for non-fraudulent):
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 30) 930
_________________________________________________________________
dense_1 (Dense) (None, 32) 992
_________________________________________________________________
dense_2 (Dense) (None, 2) 66
=================================================================
Total params: 1,988
Trainable params: 1,988
Non-trainable params: 0
To track the results, a confusion matrix was used. This counts the number of outcomes in each of the following categories:
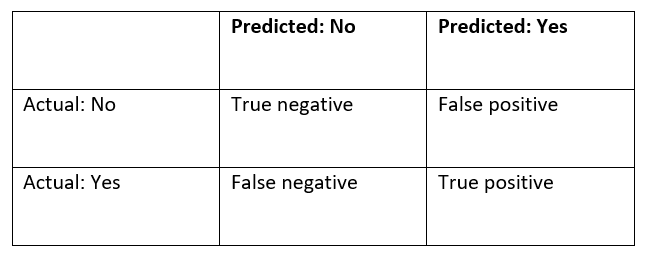
To track the results, a confusion matrix was used. This counts the number of outcomes in each of the following categories:
True negative: Correctly classified a transaction as non-fraudulent
False negative: Incorrectly classified a transaction as non-fraudulent
True positive: Correctly classified a transaction as fraudulent
False positive: Incorrectly classified a transaction as fraudulent
The results were as follows:
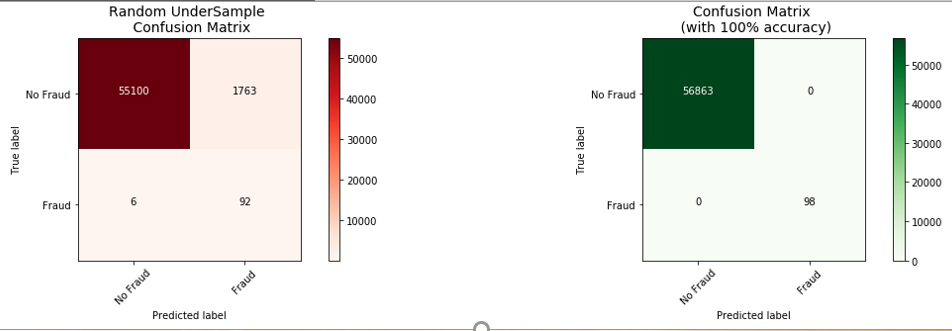
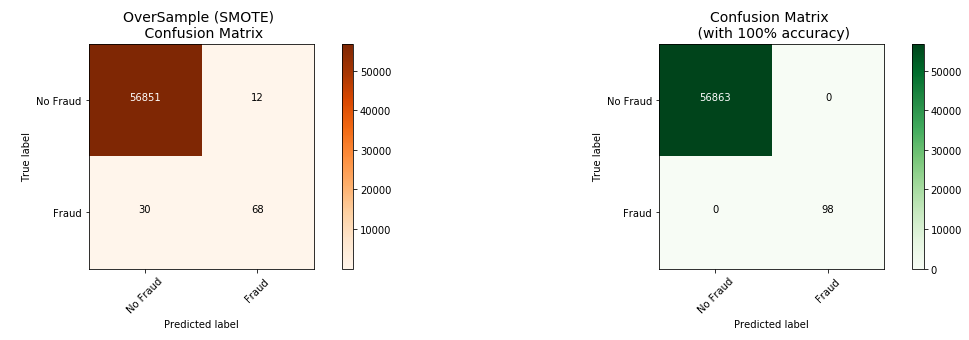
The analysis shows the following:
- The undersample was more successful at predicting fraudulent transactions, correctly predicting 92 out of 98 frauds, whereas the oversample was less accurate predicting 68 out of 98.
- The oversample performed much better with false-positives, only generating scoring 12 false-positives versus 1763 false positives produced by the undersample.
False positives, reporting a legitimate transaction as Fraudulent, can lead to negative experiences for customers; most people don’t like being told that they are being flagged as a potential fraudster! Depending upon business requirements, an organisation may prefer to tolerate more fraud to avoid the negative customer experiences.
The potential is clear
This exercise demonstrates that by applying the appropriate analysis, Machine Learning can be successful in Fraud Detection even when being trained for a highly imbalanced dataset. It has been possible to predict 92 out of 98 fraudulent transactions.
This is particularly impressive considering that the exercise was performed on an anonymised dataset without any context. We know that there were 28 input fields, however no information was supplied regarding the meaning of each field. With contextual information about the transaction history that was used to train the model, it should be possible to gain an even higher rate of detection of fraudulent transactions.
Machine Learning offers the potential to detect new fraud patterns as they emerge and to handle the tsunami of digital payments that we are seeing as people around the world make more and more digital payments. Even with a highly imbalanced dataset, Machine Learning can pick up the baton of applying AI to detect fraud that rule-based systems have successfully achieved over the past 30 years.
Tamsin Crossland