

The clash of the frameworks

Setting the scene
In the third part of our series exploring the motivations, architecture and principles driving the development of IPF, Pat Altaie, Senior Consultant, discusses the benefits of using interoperable programming frameworks.
In the IPF team, we are always trying to be reactive first, applying the concept of designing systems that are responsive, resilient, elastic and message driven (you can read more about reactive systems in The Reactive Manifesto). Being reactive was one of the things that we loved about the existing iteration of IPF and its use of Akka – the asynchronous, nonblocking framework – with which we now have a wealth of experience; and therefore, we did not want to change this reactive element unless absolutely necessary.
Our choice of Akka is not a common one in modern “enterprise” applications, which typically use the Spring Framework, and its ever-growing set of features, inside and out. The more features Spring implements, the less direct external dependencies it seems we need to declare. This is a great step for the Java community, because the point of projects such as Spring Boot is just that – to bootstrap a project quickly so that you can actually get to delivering business value quickly, and spend less time wrestling with dependencies, environment variables, WAR deployments onto application servers, and so on.
Revisiting the first blog in the IPF technology series, written by my colleague, Simon Callan exploring five common software product challenges, he pointed out ‘architecture not being easy to communicate’ as one of the signs that your product needs a shake-up. One difficult aspect to explain to new members of the team was our completely custom actor dependency injection DSL which we created to wire Akka actors together, with Spring dependencies thrown in the mix as well. This was to get around the fact that Akka does not have a dependency injection framework, and it’s not really possible to use Spring to inject actors inside other actors (more on that later).
If we were to put it into a diagram, it would probably look like this:
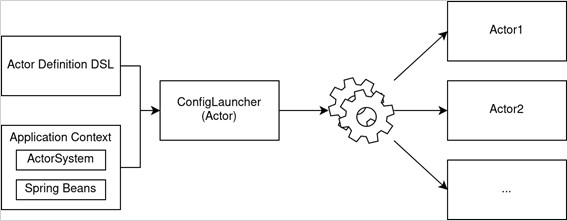
The Spring ApplicationContext would create the Akka ActorSystem, which would in turn launch an actor called ConfigLauncher. This actor would then be given the ApplicationContext containing all Spring beans, and the aforementioned actor definition DSL, and it would construct a directed acyclic graph (DAG) of all actors that need to be created, with their respective dependencies on Spring beans or other actors. Actor definitions looked like this:

Each one of these is parsed by the ConfigLauncher to reflectively load the class name defined in the class attribute, which hopefully has the right constructor arguments (“options”) – which can consist of other actors, Spring beans, or primitive types. Configuration files like this were in src/main/resources directories of most modules, and if you were a new starter, you wouldn’t have a clue what they do at first glance. Obviously, there is a class name there, but you would need help to figure out that “options” actually means “constructor arguments”. And of course, since this was a home-rolled DSL, it had no IDE support.
This DSL is probably the most extreme example of the surprises that were hiding in the original iteration of the product, but there were some others:
- Instead of using POJOs (plain-old Java objects) to represent data in the domain, we were using wrappers around a Jackson ObjectNode with getters and setters grabbing and setting specific paths in the ObjectNode’s graph.
- The actor definition DSL didn’t allow for a builder-style pattern where we specify properties we care about and have sensible defaults for others. It was all or nothing! (Or…a third option would be to have an infinite number of constructors with varying constructor arguments.)
- All projects depended on a single “core” project which meant that changes to the core would be risky as all downstream systems were potentially impacted. We later started breaking this core out into independent modules that didn’t necessarily need to be together.
These things were stacking up, so we decided that we really needed to do something different.
Ditch one, go with the other?
At first, we were obsessed with the idea that to solve these issues, we needed to do away with one framework – Akka or Spring – and exclusively use the other. Spring was the obvious choice, especially with its introduction of first-class support for Project Reactor, the nonblocking API for Java. When we first developed the Icon Payments Framework, IPF, Spring was at version 4.2, and the most interesting feature of that version of Spring was improved support for JMS and WebSockets. Wow! The modernity!
With the release of Spring 5 in 2017 (and further improvements that have been made to that over the past few years) it became a compelling argument to completely ditch the Akka framework and go totally reactive using Spring only. Some advantages of that would have been:
- Navigating the code won’t be a surprise to newcomers – everybody knows what Spring and the associated dependency injection looks like.
- Project Reactor has tooling support like IntelliJ IDEA with its Reactor debug mode.
- Better Java support from Spring (Akka has a Java API, but is natively written and used by Scala devs).
There were some issues we would need to overcome if we stuck to Spring though:
- No event sourcing/CQRS framework: in the previous blog in the IPF Technology series, Sirin discussed why we selected ES/CQRS as the way forward. Spring doesn’t natively support event sourcing (yet), so we would have had to bring in a third-party library like Axon which we had never used before.
- Consistency: No native multi-node support means you have to roll your own support for consistency (see CAP theorem).
We could have also gone Akka-only, but this was a non-starter as the two frameworks are not equivalent in terms of feature sets. There is a small amount of overlap, but there are lots of features that Spring has which Akka doesn’t, and vice versa. Another issue is that the two frameworks don’t play nicely together because Spring is not really designed for clustered deployments that are aware of each other, whereas Akka is all about location transparency and only needing the actor’s address.
It was when we were discussing the latter part that we decided that we could go with a different approach: keep using both, but with a complete separation between the Akka world and the Spring world. You’d only need to use Akka if you were dealing with the event-sourced part of the application, and use Spring dependency injection (and other features) elsewhere. And never the twain shall meet!
Integration
One final thing that needed a rethink was how we did integration. Apache Camel has served us well for the past four years, but its selection was mostly because of Akka’s support for Camel. Since then, Akka has removed direct support for Apache Camel and has instead recommended Alpakka, the Akka Streams-based integration framework. We also evaluated using other frameworks such as Spring Integration, Camel (again) through Alpakka, or Spring on its own.
We ended up settling on Alpakka for various reasons:
- Natively streaming: this means we seamlessly connect all parts of the application from consumption of the message at the boundary to persisting an ES event. Great for non-repudiation!
- Super extensible: easily add additional processing steps (operators) to the integration stream to add steps, divert the flow, peek contents, etc.
- Technology support: Supports Kafka, JMS and HTTP (via Akka HTTP) out-of-the-box, which is all we need for 99% of integrations. Lots of other protocols are supported of course; the full list can be found here.
We then wrapped Alpakka and created our own mini framework, called the Connector Framework which adds processing steps to the integration stream such as logging, correlation, backpressure, resiliency and so on. One advantage of our Connector Framework is that it doesn’t expose any of the internal Akka implementation to the outside world, which means that we can later change the internal implementation of the connector without affecting downstream systems.
Retrospective
We have been running with the delineated configuration of Akka, Spring and Alpakka for around six months now, and so far it’s looking great in performance tests in terms of CPU and memory usage, transactions per second (TPS) values, and various other non-functional metrics. As the most exercised part of the code, we have created a performance test suite for the Connector Framework itself to ensure that it takes up as little time as possible when both sending and receiving messages. It took a lot of experimentation, learning, setbacks and group decisions to find the right combination, however, we now have collective conviction that this is exactly the right approach for our needs, giving us a solid foundation to take on any payments challenge.
Patrick Altaie